Системы сквозного проектирования
А. Закис, Н. Приезжий, DataX/FLORIN
В предшествующих выступлениях и публикации мы неоднократно рассматривали технологию сквозного проектирования информационных систем, основанную на использовании CASE инструментария фирмы Cayenne (VantageTeam), сред разработки приложений фирм Informix (4GL и NewEra) и Four Seasons (SuperNova) и кодогенераторов фирмы DataX/FLORIN (GRINDERY OneStep 4GL, GRINDERY NewEra/Yourdon, GRINDERY SuperNova/Yourdon). В данном выступлении мы хотели бы рассказать о новом продукте нашей фирмы - среде быстрой разработки GRINDERY Grabber.
Технология
Прежде всего, мы хотели бы ответить на вопрос, который нам неоднократно задавали во время UnixExpo, где был представлен этот продукт: почему мы взялись за его разработку в то время, когда на рынке имеется достаточное количество разнообразных CASE средств и билдеров. Ответ прост - этот продукт "создался сам" из тех технических решений, которые мы использовали при работе над собственными проектами или предлагали нашим клиентам для того, чтобы соединить различные средства автоматизации проектирования и программирования в единый технологический процесс, и которые отсутствовали (или были недостаточно развиты) в готовых продуктах .
Что же не устраивало нас в стандартных подходах? Для ответа на этот вопрос рассмотрим две модели использования средств автоматизации: "до и от" и "от и до".
Первый подход (пропагандируемый разработчиками билдеров и "легких" CASE средств) предполагает, что CASE используется только для проектирования и ("до") создания базы данных, а разработка приложения осуществляется ("от" готовой базы) с помощью билдеров, которые обладают собственными средствами реверсинжениринга модели данных, библиотеками классов и многими другими достоинствами. На наш взгляд, основными недостатками этого подхода является то, что технологический процесс разорван - модель данных, используемая билдером, значительно беднее модели, разработанной аналитиком в CASE (или "в голове", если CASE вообще не использовался), и аналитик вынужден передавать недостающую информацию "голосом".
При использовании билдера выясняется, что стандартные библиотеки классов недостаточны для полнофункционального приложения, и каждый программист по-своему наращивает функциональность, что приводит к "лоскутному" интерфейсу. Стандартизация интерфейса может быть осуществлена либо организационными методами, либо за счет использования написанной "на коленке" библиотеки классов. В итоге, аналитик и программисты получают удобный инструментарий, но его использование не приводит ни к улучшению качества системы, ни к ускорению разработки.
Второй подход (реализованный в "тяжелых" CASE средствах, например, в VantageTeam) предполагает, что в CASE поддерживает разработку "от" анализа "до" логических моделей данных и приложения, на основе которых создается база данных и осуществляется автоматическая генерация программного кода. VantageTeam предоставляет пользователю прекрасный инструментарий для проектирования приложения:
- диаграммы содержания экранных форм (FCD - Form Contence Diagram), которые позволяют описать структуру и (в значительной степени) функциональность сложных экранных форм (предназначенных для работы с несколькими таблицами);
- диаграммы структурных схем (SCD - Structure Charts Diagram), которые позволяют описать алгоритмы программных модулей и методы работы с экранными формами (последняя задача в рамках структурного подхода достаточно элегантно решена с помощью так называемых "предопределенных модулей");
- диаграммы последовательности экранных форм (FSD - Form Sequence Diagram), которая задает общую структуру приложения. а также связывает формы и алгоритмы (методы).
Но и это не панацея. Главный недостаток этого подхода состоит в том, что идеология проектирования не учитывает реальные потребности проектировщика, который должен разработать информационную систему со стандартным интерфейсом (поскольку заказчику нужна система с легко осваиваемыми рабочими местами). Проектировщику нужны средства построения логической модели стандарта интерфейса, а не полной модели всех элементов интерфейса. Детальное проектирование каждой экранной формы (средствами FCD или в билдере) при создании стандартного интерфейса является не только нудной, но и (в большинстве случаев) вредной работой (немногочисленные, как правило, "уникальные" рабочие места гораздо быстрее и проще создавать на основе типового рабочего места, а не "с чистого листа").
Наша фирма пошла по пути проектирования стандарта. Результатом этой работы стала технология сквозного проектирования и семейство кодогенераторов GRINDERY.
Однако их область их применения существенно ограничивалась тем, что они были настроены на логическую модель данных, формируемую VantageTeam. Затраты на приобретение и освоение "тяжелого" CASE окупаются только при создании достаточно крупных систем или при "поточном" производстве, а многие возможности, предоставляемые продуктами этого класса, не столь уж необходимы для создания небольшой системы разработчиками, хорошо знающими предметную область ( и, тем более, для воспроизведения существующей системы на другой платформе, что является весьма актуальной задачей для многих систем ). И мы занялись разработкой "легкой" технологии сквозного проектирования "от" существующей базы данных. Ее основные отличия от рассмотренной выше технологии "до и от" состоят в следующем:
- при реверсинжениринге создается не физическая, а логическая модель данных, на основе которой осуществляется генерация стандартного интерфейса ;
- билдеры используются только в режиме модификации, причем внесенные изменения автоматически фиксируются и воспроизводятся при повторной генерации.
Продукт (GRINDERY Grabber v.1.0) и проект (GRINDERY Grabber v.2.x)
GRINDERY Grabber v1.0 обеспечивает:
- восстановление логической модели базы данных на основе информации, хранящейся в системных каталогах;
- интерфейс для ввода параметров, описывающих стандарт приложения;
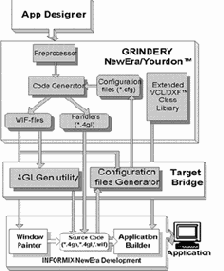
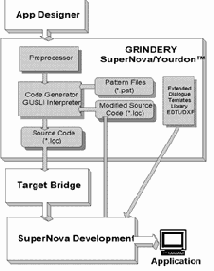
- генерацию приложения на любом языке, поддерживаемом семейством кодогенераторов GRINDERY (в настоящее время - Informix- 4GL, NewEra, SuperNova);
- фиксацию изменений, внесенных в программный код пользователем и их воспроизведение при повторной генерации;
- модификацию структуры базы данных в объеме, необходимом для эффективной работы стандартного приложения.
- GRINDERY Grabber v1.0 поддерживает:
- групповую работу над проектами и управление версиями проектов, в том числе:
- разграничение прав доступа;
- независимую разработку частей проекта;
- сборку проекта ;
- документирование проекта.
GRINDERY Grabber v1. 0 поддерживает разработку приложений для СУБД Informix, Oracle, CA OpenIngres и может работать на основных Unix и всех Windows платформах.
Принципы построения стандартного интерфейса
- Для каждой сущности (предметной таблицы базы данных) создается "рабочее место", позволяющее выполнять основные операции (INSERT, UPDATE, DELETE, QBE) с данными, содержащимися в этой таблице.
- Рабочее место позволяет работать не только с "главной" таблицей, но и с другими ("вспомогательными" для данного рабочего места) таблицами базы данных. В том случае, когда реляционная модель данных адекватно отражает связи и бизнес-правила предметной области, вспомогательными являются "таблицы-словари" ( Master tables - таблицы, из которых импортирует ключи "главная" таблица), "таблицы-потомки" (Detail tables - таблицы, которые содержат ссылки на "главную") и "таблицы-партнеры" (связанные с "главной" таблицей отношением "многое ко многому"). Вспомогательные таблицы доступны как в режиме просмотра, так и в режиме модификации (если это необходимо для данного рабочего места).
- Каждая таблица имеет в интерфейсе два представления:
- в виде одной записи, содержащей полный набор полей - детальное представление.Оно используется для добавления записей в "главную" таблицу и их модификации;
- в виде списка (браузера), который используется для навигации (поиска) по главной и вспомогательным таблицам, а также для выполнения групповых операций. При этом используется краткое представление - определяемый пользователем набор полей, достаточный для однозначной идентификации записи и содержащий наиболее часто используемую информацию (например, для таблицы "Фирма" в краткое представление целесообразно включить название фирмы и ее банковские реквизиты). Краткое представление таблицы для всех рабочих мест одинаково.
При таком подходе основная информация, необходимая для генерации приложения "считывается" из логической модели данных. Пользователю необходимо задать незначительное количество атрибутов:
- имена, под которыми должны отображаться таблицы и их колонки;
- состав предметного ключа (кодогенерация рассчитана на то, что в качестве первичного используется искусственный ключ - колонка типа SERIAL);
- форму представления колонок в графическом интерфейсе (Entry, Label etc)
- состав краткого представления таблиц;
- возможность модификации таблицы-словаря;
- необходимость и форму представления информации из таблиц-потомков и таблиц-партнеров в детальной форме;
- политику поддержки целостности при удалении.
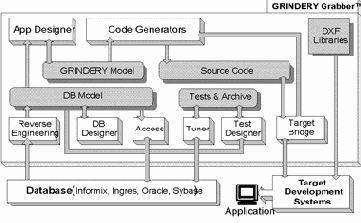
Структура GRINDERY Grabber
GRINDERY Grabber включает:
- модуль Reverse Engineering;
- модуль DB Designer;
- модуль Access;
- модуль Tuner (v.2.x);
- модуль App Designer;
- кодогенераторы GRINDERY;
- модуль Target Bridge;
- модуль Test Designer (v.2.x).
Модуль Reverse Engineering обеспечивает построение логической модели данных.
Модуль DB Designer предназначен для проектирования (v.2.x) и модификации модели базы данных.
В версии 1.0 поддерживается:
- модификация базы данных в минимальном объеме, необходимом для эффективной работы приложения (переход от предметных ключей к искусственным, создание UNIQUE CONSTRAINTS для предметных ключей, создание триггеров, поддерживающих политику Nullify, создание служебных таблиц для SuperNova);
- ведение архива пользовательского DDL.
В версии 2.х предполагается:
- навигационный интерфейс, обеспечивающий представление всех объектов базы данных, включая триггера и хранимые процедуры;
- конструктор логической модели данных;
- конструктор триггеров и хранимых процедур, основанный на синтаксической декомпозиции DDL, библиотеке шаблонов и языке подстановок.
Модуль Access обеспечивает:
- автоматическую генерацию DDL (в версии 1.0 - по шаблонам, в 2.х - генерация DDL для любой из поддерживаемых СУБД по логической модели данных, триггеров и хранимых процедур);
- исполнение DDL и ведение журнала модификации базы данных;
- синхронизацию логической модели с актуальным состоянием базы данных.
Модуль Tuner обеспечивает:
- трассировку SQL запросов;
- фиксацию времени исполнения SQL запросов;
- проведение исторических тестов (сравнение результатов исполнения SQL запросов с эталоном);
- ведение архива тестов и результатов их исполнения;
- генерацию стандартного или задаваемого пользователем структурированного отчета по результатам трассировки;
- статистическую обработку и графическое представление результатов замеров производительности.
Модуль App Designer предназначен для построения логической модели приложения и содержит:
- графический (навигационный) интерфейс ввода информации;
- генератор текстовых отчетов .
Кодогенераторы Grindery обеспечивают генерацию исходных кодов приложений на языках Informix- 4GL, NewEra, SuperNova. В состав всех кодогенераторов входят расширенные библиотеки классов (функций). Генератор для SuperNova содержит открытую библиотеку шаблонов.
Модуль Target Bridge обеспечивает:
- фиксацию изменений, внесенных пользователем (только для NewEra; для Informix- 4GL и SuperNova эта функция реализована в кодогенераторе);
- генерацию make-файла;
- оптимизацию процесса трансляции WIF-файлов (утилита 4GLGEN для NewEra).
Модуль Test Designer включает :
- конструктор тестов, основанный на открытой библиотеке шаблонов и языке подстановок;
- средства контроля полноты тестов, основанные на синтаксическом анализе SQL и логической модели базы данных;
- генератор тестов на производительность (имитация многопользовательского режима и "клонирование" SQL запросов,
- графический интерфейс представления теста и его воздействия на объекты базы данных.
Сценарии использования GRINDERY Grabber
Наша фирма предлагает следующие сценарии использования GRINDERY Grabber v.1.0
- при работе над большими проектами (и фирм занимающихся индустриальной разработкой информационных систем) GRINDERY Grabber v.1.0 может использоваться как дополнение к "тяжелому" CASE (при использовании VantageTeam, в силу совместимости формата хранения модели данных, разработка стандарта приложения не требует создания целевой базы данных).
Такое использование не только позволяет сократить количество дорогих рабочих мест, но и позволяет изменить подход к проектированию базы данных. В CASE достаточно разработать концептуальную модель данных (используя такие составные предметные ключи, ассоциативные объекты, субтипы), а ее приведения к "удобному для СУБД" виду будет сделано автоматически. Кроме того, GRINDERY Grabber позволяет провести быстрое прототипирование приложения, что позволяет провести окончательную верификацию модели данных;
- при разработке средних систем и решении задач миграции существующих систем в новую среду разработки GRINDERY Grabber может использоваться не только как средство создания конечного приложения, но и как средство сравнительной оценки разных средств разработки (поскольку приложение может быть создано и протестировано в пределах срока демо лицензии);
- при решении проблем сопровождения плохо документированных систем .
Дополнения, предусмотренные в GRINDERY Grabber v.2.x позволят использовать его:
- в качестве инструмента проектирования и отладки серверной части приложения;
- как инструмент поддерживающий миграцию существующих систем на новую СУБД. При этом поддерживается не только миграция на выбранную СУБД но и ее выбор по результатам сравнительного тестирования;
- как инструмент тестирования существующих систем. .
[]
[]
[]